Details
-
Fix
-
Status: Dismissed (View Workflow)
-
 Major
Major
-
Resolution: Works as designed
-
1.8
-
None
-
gollum:4241/ / homer:4111/ / share:8of9/data
Description
Starting Situation
- Cluster setup with two JobScheduler instances, e.g. gollum.sos and homer.sos
- Common CIFS mount between two servers
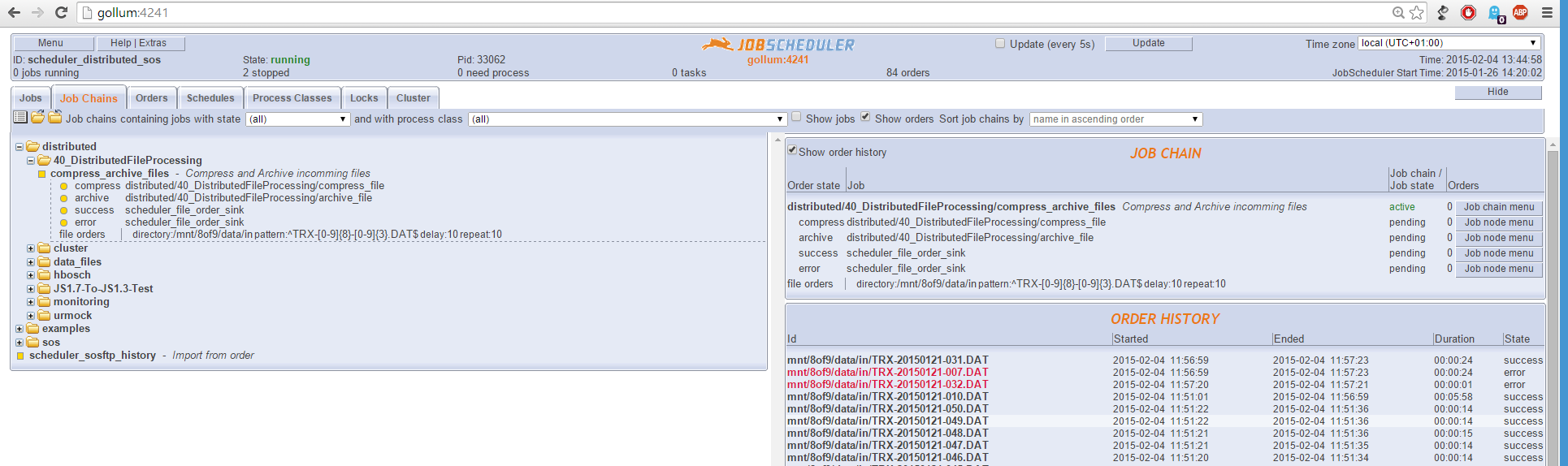
Current Behavior
- When 50 files each 2MB size are moved to the common mount point, then out of 50 files just 1-3 files are in error and the others are processed without error.
- The error _file not found_ occurs when both JobScheduler instances try to process the file, but one processes the file and removes it before the second instance can get hold of the file.
- The following log output is created:
2015-02-04 11:56:59.391+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) SCHEDULER-842 Task is going to process Order distributed/40_DistributedFileProcessing/compress_archive_files:/mnt/8of9/data/in/TRX-20150121-007.DAT, state=compress, on JobScheduler http://gollum:4241 2015-02-04 11:56:59.393+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) 2015-02-04 11:56:59.393+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) Task distributed/40_DistributedFileProcessing/compress_file:7405293 - Protocol starts in /home/jenkins/sos-berlin.com/jobscheduler/scheduler_distributed_sos/logs/task.distributed,40_DistributedFileProcessing,compress_file.7405293.log 2015-02-04 11:56:59.394+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) SCHEDULER-918 state=starting (at=never) 2015-02-04 11:56:59.394+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) SCHEDULER-987 Starting process: '/bin/sh' '-c' '"/tmp/jenkins/sos.Vc88iD"' 2015-02-04 11:57:21.606+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) compress_file : job starting 2015-02-04 11:57:21.606+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) . 2015-02-04 11:57:21.606+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) . 2015-02-04 11:57:21.606+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) . 2015-02-04 11:57:21.606+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) Processing File /mnt/8of9/data/in/TRX-20150121-007.DAT 2015-02-04 11:57:21.606+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) . 2015-02-04 11:57:21.606+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) . 2015-02-04 11:57:21.606+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) . 2015-02-04 11:57:21.606+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) START Compress file :TRX-20150121-007.DAT 2015-02-04 11:57:21.606+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) CMD> gzip -cv /mnt/8of9/data/in/TRX-20150121-007.DAT > /mnt/8of9/data/in/TRX-20150121-007.DAT.gz 2015-02-04 11:57:21.606+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) . 2015-02-04 11:57:21.606+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) . 2015-02-04 11:57:21.606+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) CMD> gzip -cv /mnt/8of9/data/in/TRX-20150121-007.DAT > /mnt/8of9/data/in/TRX-20150121-007.DAT.gz : unsuccessful , Exit 99 2015-02-04 11:57:21.606+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) gzip: /mnt/8of9/data/in/TRX-20150121-007.DAT: No such file or directory 2015-02-04 11:57:23.032+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) SCHEDULER-915 Process event 2015-02-04 11:57:23.032+0100 [ERROR] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) SCHEDULER-280 Process terminated with exit code 99 (0x63) 2015-02-04 11:57:23.033+0100 [info] (Task distributed/40_DistributedFileProcessing/compress_file:7405293) SCHEDULER-843 Task has ended processing of Order distributed/40_DistributedFileProcessing/compress_archive_files:/mnt/8of9/data/in/TRX-20150121-007.DAT, state=compress, on JobScheduler http://gollum:4241 2015-02-04 11:57:23.033+0100 [info] set_state error, Job /scheduler_file_order_sink 2015-02-04 11:57:23.127+0100 [info] (Task scheduler_file_order_sink:7405246) SCHEDULER-842 Task is going to process Order distributed/40_DistributedFileProcessing/compress_archive_files:/mnt/8of9/data/in/TRX-20150121-007.DAT, state=error, on JobScheduler http://gollum:4241 2015-02-04 11:57:23.127+0100 [WARN] (Task scheduler_file_order_sink:7405246) SCHEDULER-339 File does not exist and can therefore neither be moved nor removed: /mnt/8of9/data/in/TRX-20150121-007.DAT 2015-02-04 11:57:23.128+0100 [info] (Task scheduler_file_order_sink:7405246) SCHEDULER-843 Task has ended processing of Order distributed/40_DistributedFileProcessing/compress_archive_files:/mnt/8of9/data/in/TRX-20150121-007.DAT, state=error, on JobScheduler http://gollum:4241 2015-02-04 11:57:23.128+0100 [info] SCHEDULER-945 No further job in job chain - order has been carried out 2015-02-04 11:57:23.128+0100 [info] SCHEDULER-940 Removing order from job chain
Resolution
- This problem has been tested to occur if the latency of the common mount point exceeds the time required to process the incoming file by a job chain, e.g. the file appears to one JobScheduler instance with a delay of 3s and during that delay another instance has processed the file completely by a job chain.
- We cannot modify the behavior to compensate such delays without serious impact on the functionality of this feature that requires timely processing of incoming files.
- We tested with JobScheduler 1.9-SNAPSHOT on Windows x64 and no errors in the behavior have been found as JobScheduler is working as expected.
- in parallel tests with CISF/Samba drives due to the shared drive's latency files appeared at a different point in time to the individual cluster members. This caused some conflicts between cluster members that resulted in the above error.
- To compensate the latency which depends upon individual system setup, the application can create a delay in the first node of the job chain that corresponds to the latency value (sleep).
- For fast shared drives (as simulated in Windows Cluster on one computer) a forced delay of 3-5 seconds has avoided any conflict.